Oracle
Oracle is one of the largest vendors in the enterprise IT market and the shorthand name of its flagship product, a relational database management system (RDBMS) that's formally called Oracle Database. The database software sits at the center of many corporate IT environments, supporting a mix of transaction processing, business intelligence and analytics applications.
In 1979, Oracle Corp. was the first company to commercialize an RDBMS platform, and it's still the leading database vendor by a wide margin in terms of revenue. Driven primarily by sales of Oracle Database, it had a 40.4% share of worldwide database software revenues in 2016, according to Gartner; that was down two percentage points from 2015, but still twice the share of second-place Microsoft.
In the ensuing decades after launching the RDBMS technology, Oracle greatly expanded its product portfolio through internal development and numerous acquisitions. It now also sells several other databases, multiple line of business applications, data analytics software, middleware, computer systems, data storage equipment, development tools and other technologies. In addition, Oracle is working to establish itself as a leading cloud computing vendor, after initially being slow to embrace the cloud.
But Oracle Database is still the technology that is most commonly associated with the company; it's also the primary data management platform for Oracle's applications and the data warehouse, BI and analytics systems that Oracle offers to customers.
Oracle Database's architecture
Like other RDBMS software, Oracle Database is built on top of SQL, a standardized programming language that database administrators, data analysts and other IT professionals use to manage databases and query the data stored in them. The Oracle software is tied to PL/SQL, an implementation developed by Oracle that adds a set of proprietary programming extensions to standard SQL -- a common practice among RDBMS vendors. Oracle Database also supports programming in Java, and programs written in PL/SQL or Java can be called from the other language.
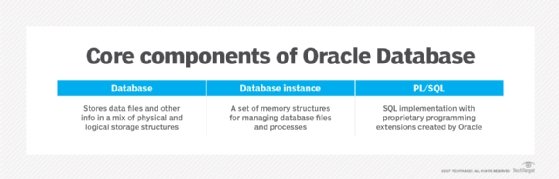
Also, like other relational database technologies, Oracle Database utilizes a row and column table structure that connects related data elements in different tables to one another; as a result, users don't have to store the same data in multiple tables to meet processing needs. The relational model also provides a set of integrity constraints to maintain data accuracy; those checks are part of a broader adherence to the principles of atomicity, consistency, isolation and durability -- known as the ACID properties -- and are designed to guarantee that database transactions are processed reliably.
From an architectural standpoint, an Oracle database server includes a database for storing data and one or more database instances for managing the files contained in the database. Databases have a mix of physical and logical storage structures. Physical storage structures include data files, control files that contain metadata about the database and online redo log files that document changes to data. Logical storage structures include data blocks; extents, which group together logically contiguous data blocks; segments, which are sets of extents; and tablespaces, which serve as logical containers for segments.
An Oracle database instance is built around a set of caches, called the system global area (SGA), that contain pools of shared memory; an instance also includes processes running in the background that manage I/O functions and monitor database operations to optimize performance and reliability. Separate client processes run the application code for users connected to an instance, while server processes manage interactions between the client processes and the database. Each server process is assigned a private memory region called a program global area, separate from the SGA.
Oracle's origins and current versions
Longtime CEO Larry Ellison and associates Bob Miner and Ed Oates founded what eventually became Oracle Corp. in 1977, originally as a consulting services company called Software Development Laboratories (SDL). Starting with a $2,000 investment, they set out to prove that relational databases -- then a fledgling technology that had only been developed in prototype form at IBM -- could be commercially viable.
SDL named its RDBMS Oracle, initially without Database included, after a project that the three founders worked on for the CIA. In 1978, SDL created a first version of the software that was never released as a product. Oracle Version 2 followed the next year, becoming the first relational database on the market. The company changed its name to Relational Software Inc. at that point; in 1982, it became Oracle Systems Corp., which was shortened to Oracle Corp. in 1995.
As of mid-2017, Oracle has released 11 major updates of the RDBMS since Version 2, culminating with Oracle Database 12c, which became available in 2013 and was enhanced in a Release 2 version that debuted in September 2016. The first 12c release added a multi-tenant architecture that enables users to configure large numbers of operational databases in a single container database, and then to manage them as one at the container level. The extra-cost Oracle Multitenant technology was designed to streamline upgrades, backups and other administration tasks on the pluggable databases, as Oracle calls them.
Oracle Database 12c also included native support for JSON documents and introduced Oracle Database In-Memory, an in-memory processing engine sold as an optional add-on. In addition, Oracle touted 12c as "designed for the cloud," and later made Release 2 available only in the cloud at first, before opening it up for on-premises use in March 2017. Oracle Database 12c Release 2 added support for sharding large databases into horizontal partitions with their own server and storage resources; it also boosted the performance of Oracle Database In-Memory and expanded the features of Oracle Multitenant.
In August 2017, Oracle disclosed plans to shift to an annual release schedule on the database software, with the last two digits of the year used as the version number of the corresponding release. That approach is due to start in 2018; as a result, the company will jump on numbering from 12c to Oracle Database 18, which will be followed by Oracle Database 19 and so on. No more "dot" releases are planned under the revised release cycle, but Oracle said software patches and bug fixes will be issued quarterly in two forms: release updates that address known issues in the database, and release update revisions that fix issues subsequently found in the updates.
Earlier versions of Oracle Database
Looking back chronologically at the RDBMS software's development, Oracle Version 3 was released in 1983. Written in C, it was ported to run on a mix of mainframe, minicomputer and PC systems, expanding the technology's availability beyond the Digital Equipment Corp. PDP-11 minicomputers supported by Version 2 and setting the stage for broader adoption by users.
Oracle Version 4 followed in 1984 with read consistency, which provided users with consistent views of data. Version 5 came out the next year, adding support for client-server computing and querying across distributed databases. Version 6, released in 1988, introduced PL/SQL and features such as row-level locking and hot backups of databases while they were being used.
Adopting a new naming convention for the software, in 1992, Oracle shipped an Oracle7 update that included stored procedures, triggers and declarative referential integrity, among other new features. Five years later, Oracle8 added support for object-oriented programming, turning the software into a hybrid, object-relational database platform.
In 1999, Oracle8i Database -- a separate version from Oracle8, with another naming format -- introduced internet capabilities via the addition of Java and HTTP support. Oracle 9i Database was released in 2001, bringing with it XML support and Oracle's Real Application Clusters (RAC) technology, which enabled users to distribute databases across multiple servers in a clustered environment for improved uptime and availability.
Oracle Database 10g was released in 2003 with yet another naming approach; it built upon the RAC setup by adding the foundations of a grid computing infrastructure that supported distributed processing across large numbers of commodity computers.
Next up was Oracle Database 11g in 2007, which formalized and expanded the Oracle Grid Infrastructure technology and included a variety of new management and administration tools. Along with the 12c releases, the 11g software can also be used as the foundation for the Oracle Database Cloud Service, which is available as a standard cloud offering or in a bare-metal configuration with dedicated hardware.
Oracle Database editions
Oracle Database is available for licensing in four separate editions that provide different levels of functionality and scalability. Oracle Database Enterprise Edition includes all of the software's features and is designed for use by large organizations running high-volume transaction processing, data warehousing, analytics and internet applications. The Standard Edition provides a more limited set of features for workgroup and departmental applications; there are three versions of it, including a Standard Edition 2 that became available with later releases of Oracle Database 12c.

In addition to conventional stand-alone licensing for on-premises implementations, Oracle Database Enterprise Edition can be licensed for deployment on the Exadata Database Machine, a bundled appliance optimized for the database software that is part of Oracle's engineered systems product line.
Enterprise Edition can also be licensed in three different permutations with varying features as part of the Oracle Database Cloud Service, plus a fourth configuration for a cloud version of Exadata. Standard Edition 2 is available for licensing as part of the Oracle Database Cloud Service, as well.
Oracle also offers Oracle Database Personal Edition for on-premises use; it provides a single-user development and deployment license with a full set of the software's features and options, except for the RAC technology. Finally, there's the Express Edition, or XE; it's a free, entry-level edition that runs on a single CPU and is limited to 11 GB of user data and 1 GB of memory. The company didn't offer XE licenses with Oracle Database 12c, but an 11g version can still be downloaded as of mid-2017.
Key database features and options
Oracle Database includes a long list of standard features, add-on options and management packs in various functional categories, including high availability, scalability, performance, security and analytics. In addition to Oracle Multitenant, Oracle Database In-Memory and RAC, some of the notable extra-cost items available as part of Enterprise Edition include modules for automatic workload management, database lifecycle management, performance tuning, online analytical processing (OLAP), partitioning, data compression, and management of spatial and graph data.
An Oracle Advanced Analytics option supports in-database SQL querying and open source R algorithms for a wider range of analytical processing. High availability functions include application continuity and automatic block repair tools, plus Data Guard and Active Data Guard, which offer a set of services for creating backup databases to provide disaster recovery capabilities and to protect against data corruption.
Data stored in Oracle Database can be encrypted to ensure data security, and both the Standard and Enterprise editions support network encryption and strong authentication. Many other security features are available as add-on features in Enterprise Edition. For example, Oracle Key Vault software keeps all the encryption keys in one place to make it easier to decrypt data. With Oracle Advanced Security, data can be encrypted transparently and redacted, making it possible to share data with other users without letting them see confidential information that they aren't supposed to access.
The Oracle Data Masking and Subsetting Pack enables data to be further encrypted or otherwise masked when being used for development and testing, and Oracle Label Security helps database administrators (DBAs) put boundaries on who can see what data; it enables fine-grained access control by assigning a classification, or label, to individual rows of data and then allowing users to view only the rows that match their label authorization.
Oracle Database Enterprise Edition also has available security features to help DBAs determine who can access data in the first place, such as Oracle Database Vault, which prevents users from accessing data they don't have privileges to see. Oracle Database Vault also does privilege analysis, so users can be given the lowest possible access level they require to do their job effectively. Oracle Audit Vault and Database Firewall supports policy-based auditing of data access to monitor usage; it also monitors SQL activity and prevents unauthorized SQL traffic from reaching databases.
Oracle's other database products
Along with Oracle Database, Oracle offers several other database technologies, most of them added through acquisitions.
Most notably, when Oracle acquired computer vendor Sun Microsystems Inc. in 2010, it also got the MySQL database, which Sun had bought in 2008. MySQL is a popular open source relational database that is part of the LAMP software stack for web applications, along with the Linux operating system; Apache web server; and PHP, Perl or Python as a programming language. Oracle sells commercial versions of MySQL in addition to maintaining the freely available community edition.
Oracle also markets TimesTen, an in-memory relational database that it acquired in 2005, and Essbase, a multidimensional database for use in OLAP applications, which Oracle obtained when it purchased Hyperion Solutions Corp. in 2007.
In addition, Oracle sells a NoSQL database that was developed internally and initially released in 2011. That product, called Oracle NoSQL Database, is a key-value data store; like other NoSQL technologies, it's an alternative to relational databases for some processing tasks, such as big data applications involving unstructured and semistructured data.
Other core Oracle technologies
Beyond its databases, key products offered by Oracle include Oracle E-Business Suite, Oracle Fusion Applications and other business application software; the Exadata appliance; Oracle Enterprise Manager; Oracle Fusion Middleware; and analytics tools such as Oracle Business Intelligence 12c and Oracle Big Data Discovery.
Oracle has gained more than just new databases from its aggressive acquisition strategy. For example, the company greatly broadened its business applications product portfolio through a series of acquisitions, including two major deals that helped turn it into one of the top vendors in that part of the enterprise software market.
Oracle introduced its first applications, a set of internally developed accounting software apps called Oracle Applications, in 1990; 10 years later, it launched E-Business Suite, a wider collection of enterprise resource planning (ERP), finance, human resources (HR) and supply chain management applications. Then, in 2005, Oracle purchased PeopleSoft Inc., giving it PeopleSoft's own ERP, finance and HR applications and the JD Edwards software that PeopleSoft bought two years earlier. Oracle followed that up by acquiring customer relationship management software vendor Siebel Systems in 2006.
Elements of all those product lines were combined into the Oracle Fusion Applications suite, which Oracle released in 2011 after lengthy development delays. However, it also still develops and sells the individual lines, and has said it will continue to do so indefinitely. In addition, the company has created a full set of cloud-based enterprise business applications, and it augmented that by acquiring NetSuite, a vendor of cloud applications primarily for small to midsize organizations, in late 2016.
Altogether, Oracle has bought more than 100 companies since 2005, bulking up its holdings in various technology areas. In addition to Essbase, for example, the Hyperion acquisition gave Oracle a wide range of enterprise performance management and analytics tools. Another big acquisition came in 2008, when Oracle bought BEA Systems, a vendor of middleware and service-oriented architecture tools.
An added hardware focus for Oracle
The Sun acquisition led Oracle directly into the hardware business after some smaller steps preceding the deal; for example, the release of an initial version of the Exadata system in 2008. Oracle offers Unix servers based on Sun's SPARC microprocessor architecture and the Solaris operating system, plus a line of x86-based servers that support Windows, Linux and Solaris. However, Sun's server revenues were declining sharply before the acquisition, and Oracle has since dropped out of the top-five rankings of server vendors with both Gartner and rival market research outfit IDC.
In addition to continuing Sun's hardware development, Oracle has expanded the engineered systems family of bundled hardware and software that debuted with Exadata -- it now also includes products such as Oracle SuperCluster, Oracle Big Data Appliance, Exalogic Elastic Cloud and Exalytics In-Memory Machine. The engineered systems are special-purpose machines designed primarily to support high-performance applications.
Because Sun was the creator of Java, the acquisition also brought the widely used open source programming language into Oracle's purview and paved the way for Oracle to lead its development. Things haven't gone entirely smoothly on that, though. A Java 8 update originally due out in 2013 was delayed by a year, and a planned Java 9 release was pushed back from September 2016 to July 2017, and then again to September 2017.
Long before the Sun deal, Oracle made one other highly publicized effort to get into the hardware business: In the mid-1990s, Ellison pushed the idea of the network computer (NC), a thin-client system that he envisioned as a lower-cost alternative to PCs. Oracle set up a division to develop and sell NCs, and it convinced vendors such as IBM and -- ironically, as it turned out -- Sun to create similar devices. But the concept didn't take off, and Oracle discontinued its NC operation in 1999.
As adoption of Oracle Database grew and Oracle began broadening its product portfolio into other areas, Ellison became one of the highest-profile -- and most colorful and controversial -- executives in the IT industry. He was Oracle's CEO until 2014, when he stepped down from that position and became CTO and executive chairman of the board. Oracle is currently run by co-CEOs Safra Catz and Mark Hurd, but its product development operations continue to report directly to Ellison.
At one point, Ellison dismissed the cloud as a passing fad. More recently, Oracle has invested heavily in cloud computing, releasing a full suite of cloud-based infrastructure, platform, application and data services intended to enable customers to migrate their entire data centers to the Oracle Cloud platform. The company also offers an on-premises managed service called Oracle Cloud at Customer, through which its public cloud technologies are deployed and run at customer sites.
Continue Reading About Oracle
Dig Deeper on Oracle database administration
-
![]()
The roots of Oracle's cloud evolution: A 20-year review
By: Chris Kanaracus
-
![]()
How to manage Oracle database upgrades and annual releases
By: George Lawton
-
![]()
Explore data integration products for your organization
By: Mary Shacklett
-
![]()
Oracle Database 19c new features and what users need to know
By: Craig Stedman



