Oracle announced the availability of Oracle Enterprise Manager 13.5 today, bringing a series of new database management and analysis capabilities.
Oracle Enterprise Manager 13.5, also referred to as Oracle Enterprise Manager 13c Release 5, is the first major update for the management platform since January 2020 when the 13.4 release became available. Oracle Enterprise Manager (EM) provides management, deployment, migration and optimization capabilities for Oracle databases running on premises, as well as in the cloud. Among the new features in the 13.5 update is an on-premises to Oracle Cloud Infrastructure database migration tool. The 13.5 update also provides a new automatic workload analysis feature to optimize performance.
Among the many users of Oracle Enterprise Manager is Communications Test Design Inc. (CTDI) in West Chester, Pa. Naveen Garg, senior manager of database administration at CTDI explained that his organization has more than 100 operation centers across the world handling repair and logistics for IT customers. The applications supporting those branches have an Oracle back end.
"Monitoring and managing these Oracle databases is key to ensuring our operations are working effectively, 24x7," Garg said. "We rely on EM trigger alerts and also manage the Oracle estate at CTDI."
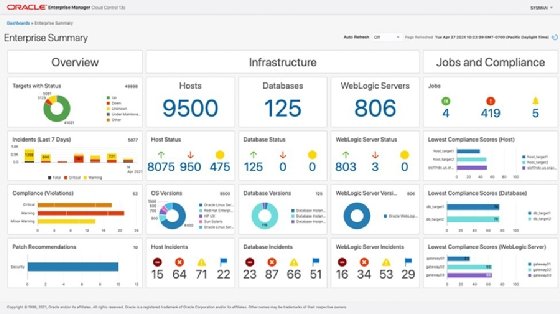
Oracle Enterprise Manager 13.5 integrates an enterprise summary dashboard that gives administrators visibility into running databases.
Database optimization improvements
Garg said that of all the features in Oracle Enterprise Manager, the most valuable for him are the tuning and diagnostic capabilities.
"We are looking forward to the new and improved features around ASH [Active Session History analytics] and the SQL advisors to help us keep our Oracle databases running efficiently," Garg said.
Mughees Minhas, vice president of overall database product management at Oracle, said Enterprise Manager 13.5 includes an Automatic Workload Analysis capability. The feature constantly compares database performance, whether on premises or in the cloud, against the expected baseline performance. If there is any divergence in performance, Enterprise Manager will alert the database administrator and provide insight into corrective actions.
Minhas said the workload analysis can be configured for a specific threshold. For example, if performance degrades by 5%, Enterprise Manager can be configured to remediate the underlying issue to bring performance back up to the baseline levels.
Monitoring and managing these Oracle databases is key to ensuring our operations are working effectively, 24x7.
Naveen GargSenior manager, CTDI
Minhas said that while Enterprise Manager has its own interface for showing metrics, organizations have wanted to be able to use other analytics tools for more complex analysis.
"Enterprise Manager has great information on performance and configuration metrics," Minhas said. "So, if you want to really do some analytics on it, you can actually extract the data from Enterprise Manager, put it in an autonomous data warehouse and then you can do any analysis you want for forecasting, capacity planning or performance planning."
Cloud and on-premises database management features
According to Minhas, Oracle Enterprise Manager 13.5 improves on past versions with a native integration to Oracle's cloud.
Enterprise Manager now understands the different configuration and operational parameters between on-premises and cloud database deployments. The goal is to enable organizations to manage all deployments of Oracle databases, whether in the cloud or on premises with a single platform.
"This awareness really makes it much more seamless to manage your hybrid cloud estate through Enterprise Manager," he said.