
Getty Images/iStockphoto
Dig into Oracle Cloud's Always Free offerings
Oracle's Always Free services let developers build and experiment with cloud-native apps without incurring costs. There are, however, important limitations to note.

Developers are an essential aspect of any platform, and cloud operators covet them as users. To lure developers to their platforms, cloud providers offer incentives. Developers should be informed about these incentives, and the platform itself, to make smart choices.
One way cloud vendors incentivize adoption is through SDKs and free trial periods for select services. Limited trial periods and free services -- such as those within the Oracle Cloud Always Free portfolio -- let developers test cloud services before they commit.
To gain a competitive edge, some cloud providers, including Oracle, offer a broad range of limited-capacity services in their always-free categories. Developers do not have to pay for these services, regardless of how long they use them.
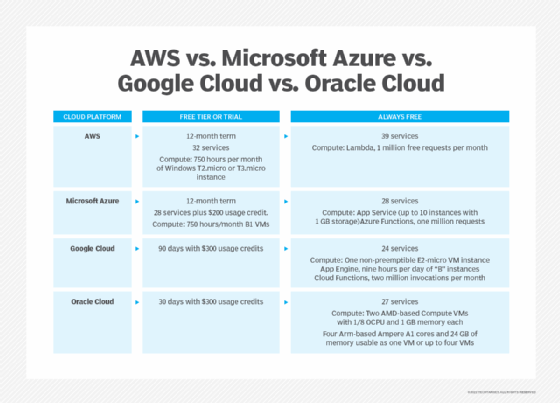
Oracle expanded its Always Free service portfolio for Oracle Cloud Infrastructure (OCI) in June 2021. The expansion included free resources for compute, databases and app development. AWS' Always Free tier, by comparison, includes offers for Lambda, app development and other services or use cases -- but does not include traditional cloud compute instances on Amazon EC2.
Oracle Cloud Always Free offerings
Oracle Cloud gives developers the resources they need to build working applications, not just Hello World exercises. Resources in the Always Free tier -- including Oracle's autonomous database services and APEX low-code development environment, the Terraform-based Resource Manager and Bastion host service -- are intended to help new cloud developers design and implement modern, cloud-native applications.
Always Free also includes Arm-based Ampere A1 instances to encourage developers to investigate the technology.
The Always Free tier complements Oracle's 30-day free trial period, which provides $300 in usage credits for a broader range of services and higher capacity limits. The table below illustrates the significant capacity differences between Oracle Cloud's two free offerings.

As of early 2022, the Always Free tier included 27 services across four categories: IaaS; PaaS and app development; managed database; and resource management and automation.
IaaS
- AMD-based Compute
- Block Volume
- Flexible Load Balancer
- Virtual Cloud Networks
- Arm-based Ampere A1 Compute
- Object Storage
- Flexible Network Load Balancer
- Site-to-site VPN
- Outbound Data Transfer
- Archive Storage
- VPN Connect
Managed database
- Autonomous Data Warehouse
- NoSQL Database
- Autonomous Transaction Processing
- Autonomous JSON Database
Resource management and automation
- Resource Manager (Terraform)
- Vault (key management)
- Bastions
- Monitoring
- Logging
- Security Advisor
- Service Connector Hub
- Application Performance Monitoring (APM)
- Security Zones
PaaS and app dev
- APEX Application Development
- Notifications (pub/sub)
- Content Management Starter Edition
Oracle Cloud vs. AWS vs. Microsoft Azure vs. Google Cloud
Major cloud vendors offer both limited-term free tiers and always-free services. Free tiers or trials include a broader range of services for a limited time, while always-free tiers have fewer services with tighter usage limits.
Using Oracle Always Free services
Users first setting up an Oracle Cloud account qualify for a $300 usage credit applicable to any OCI service. In the Oracle Cloud management UI, Always Free options are clearly indicated. An example of this is seen in Figure 3. Oracle provides templates to configure multifaceted deployments, such as a cloud-native application or its APEX low-code database application, to use Always Free resources.
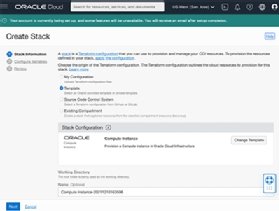
Cloud developers can also use Oracle's Resource Manager with Terraform stacks to deploy resources. As Figure 4 shows, Oracle provides stack templates for this task.
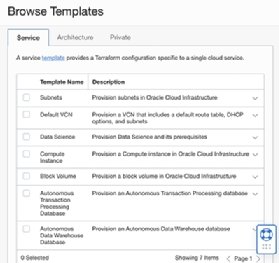
Templates are available for services including compute instances, virtual cloud networks (VCNs) and block volumes, as shown in Figure 5.
Oracle Cloud's Always Free service portfolio is sufficient to build mock-ups of most types of enterprise applications. It is particularly useful for those planning database-backed applications, such as e-commerce systems or data warehouses, using Oracle's Autonomous Database and APEX low-code development environment.
Editor's Note: This article is one of the last pieces longtime TechTarget contributor Kurt Marko wrote for us before he passed away in January 2022. Kurt was an experienced IT analyst and consultant, a role in which he applied his broad and deep knowledge of enterprise IT architectures. You can explore all the articles he authored for TechTarget on his contributor page.







