Java
What is Java?
Java is a widely used programming language expressly designed for coding applications and services used in the distributed environment of the internet. It was designed in 1995 to have the look and feel of the C++ programming language, but is simpler to use and enforces an object-oriented programming (OOP) model.
Key characteristics of Java
Here are the main characteristics of Java that differentiate it from many other languages and make it a great choice for coding web applications:
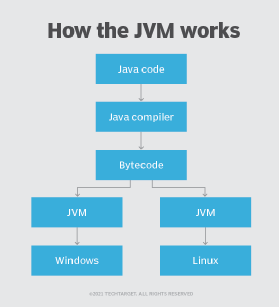
- Programs created in Java offer portability in a network. In Java, the source code is compiled into bytecode, which can run anywhere in a network, on a server or on a client that has a Java virtual machine (JVM). In contrast, many other programming languages compile code into platform-specific binary files, so programs written for a particular platform (e.g., Windows) cannot run on other platforms (e.g., Mac or Linux).
- Java is object-oriented. Java was mainly built as an object-orientated language, where a programmer-created object is made up of data as fields or attributes and code as procedures or methods. Java also uses an automatic garbage collector to manage object lifecycles and memory once the object is no longer in use. That said, memory leaks can occur when an object that's no longer being used is stored in a container.
- Java code is robust. Java code deals with failures and unpredictable conditions well, as Java objects contain no references to data external to themselves or other known objects. As a result, an instruction cannot include the address of data stored in another application or in the operating system (OS) itself, thus preventing the program and even the operating system from terminating or crashing.
- Data is secure. Java does not use pointers, which can be unsecured. Data converted to bytecode by Java is also not readable to humans. Additionally, Java will run programs inside a sandbox to prevent changes from unknown sources.
- Java applets offer flexibility. A Java applet is executed on the client rather than on the server. It also has other characteristics designed to make it run fast.
- Java is easy to learn. With a simple syntax that's similar to C++, Java is relatively easy to learn, especially for those with a background in C or C++.
What is a Java Virtual Machine?
A JVM provides a virtual and portable execution environment to run Java applications. After the source code is compiled into bytecode, the JVM interprets the bytecode into code that will run on computer hardware. It also makes several checks on each object to ensure integrity.
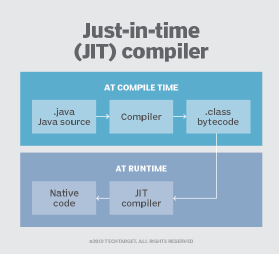
As an alternative to interpreting one bytecode instruction at a time, the JVM includes an optional just-in-time (JIT) compiler that dynamically compiles bytecode into executable code. In many cases, the dynamic JIT compilation is faster than the virtual machine interpretation.
Why is Java popular?
There are many reasons why Java is a popular programming language for a wide variety of internet applications. One is that it's easy for developers to write programs that employ popular software design patterns and best practices using the various components found in Java Platform, Enterprise Edition (Java EE). For example, frameworks such as Struts and JavaServer Faces all use a Java servlet to implement the front controller design pattern for centralizing requests. Java EE environments can be used in the cloud as well, so developers can build, deploy, debug and monitor Java applications in the cloud at a scalable level.
Another reason for Java's popularity is its broad ecosystem. A big part of this ecosystem is the variety of open source and community built projects, software platforms and APIs. For example, the Apache Foundation hosts a variety of projects written using Java, including simple logging frameworks for Java (SLF4J), both Yarn and Hadoop processing frameworks, microservices development platforms and integration platforms. The Java ecosystem also includes many in-built functions and libraries that can be used to develop applications without having to write new functions from scratch.
The language's major characteristics have also played a part in its success. For one, Java is object-oriented, so it allows for pieces of code blueprints to be reused across programs. It is also multithreaded, meaning it allows for the creation of multiple execution threads with each thread concurrently executing specific tasks. Finally, Java is popular because it is secure, architecture-neutral and can offer high performance for a wide range of applications.
Java platforms
The three key platforms upon which programmers can develop Java applications are as follows:
- Java SE. Simple, standalone applications are developed using Java Standard Edition. Formerly known as J2SE, Java SE provides all the APIs needed to develop traditional desktop applications.
- Java EE. The Java Enterprise Edition, formerly known as J2EE, is commonly used to create server-side components that can interact with internet-based clients, including web browsers, CORBA-based clients, and REST- and SOAP-based web services.
- Java ME. Java's lightweight platform for mobile development and embedded device development is known as Java Micro Edition, formerly known as J2ME.
Main uses of Java
Java can be used to create complete applications that can run on a single computer or be distributed among servers and clients in a network. It can also be used to build a small application module or applet for use as part of a webpage.
It is the most popular programming language for Android smartphone applications. Java is preferred by many Android developers because of its security, object-oriented paradigms, regularly updated and maintained feature sets, use of JVM and frameworks for networking, IO and threading.
Java is also among the most favored for the development of edge devices and internet of things (IoT) solutions. Many modern games are also built in Java. Additionally, Java is increasingly used to create applications in these areas:
- Cloud computing.
- Artificial intelligence (AI).
- Big data.
Criticisms of Java
Although Java is widely used, it still has fair criticisms. Java syntax is often criticized for being too verbose. In response, several peripheral languages have emerged to address these issues, including Groovy. Due to the way Java references objects internally, complex and concurrent list-based operations slow the JVM. The Scala language addresses many of the shortcomings of the Java language that reduce its ability to scale.
Learn more about Java and why it was designed to be platform independent. Explore seven benefits of Java and the top Java programming tools used in application development.







