distributed database

A distributed database is a database that consists of two or more files located in different sites either on the same network or on entirely different networks. Portions of the database are stored in multiple physical locations and processing is distributed among multiple database nodes.
A centralized distributed database management system (DDBMS) integrates data logically so it can be managed as if it were all stored in the same location. The DDBMS synchronizes all the data periodically and ensures that data updates and deletes performed at one location will be automatically reflected in the data stored elsewhere.
By contrast, a centralized database consists of a single database file located at one site using a single network.
Features of distributed databases
When in a collection, distributed databases are logically interrelated with each other, and they often represent a single logical database. With distributed databases, data is physically stored across multiple sites and independently managed. The processors on each site are connected by a network, and they don't have any multiprocessing configuration.

A common misconception is that a distributed database is a loosely connected file system. In reality, it's much more complicated than that. Distributed databases incorporate transaction processing, but are not synonymous with transaction processing systems.
In general, distributed databases include the following features:
- Location independent
- Distributed query processing
- Distributed transaction management
- Hardware independent
- Operating system independent
- Network independent
- Transaction transparency
- DBMS independent
Distributed database architecture
Distributed databases can be homogenous or heterogeneous.
In a homogenous distributed database system, all the physical locations have the same underlying hardware and run the same operating systems and database applications. Homogenous distributed database systems appear to the user as a single system, and they can be much easier to design and manage. For a distributed database system to be homogenous, the data structures at each location must be either identical or compatible. The database application used at each location must also be either identical or compatible.
In a heterogeneous distributed database, the hardware, operating systems or database applications may be different at each location. Different sites may use different schemas and software, although a difference in schema can make query and transaction processing difficult.
Different nodes may have different hardware, software and data structure, or they may be in locations that are not compatible. Users at one location may be able to read data at another location but not upload or alter it. Heterogeneous distributed databases are often difficult to use, making them economically infeasible for many businesses.
Advantages of distributed databases
There are many advantages to using distributed databases.
Distributed databases are capable of modular development, meaning that systems can be expanded by adding new computers and local data to the new site and connecting them to the distributed system without interruption.
When failures occur in centralized databases, the system comes to a complete stop. When a component fails in distributed database systems, however, the system will continue to function at reduced performance until the error is fixed.
Admins can achieve lower communication costs for distributed database systems if the data is located close to where it is used the most. This is not possible in centralized systems.
Types of distributed databases
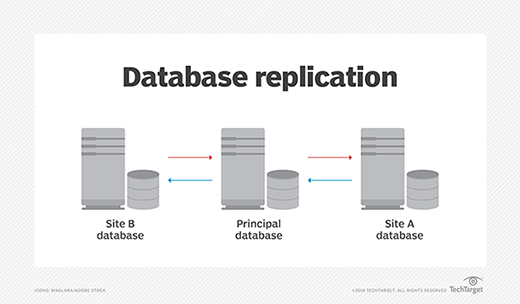
Replicated data is used to create instances of data in different parts of the database. By using replicated data, distributed databases can access identical data locally, thus avoiding traffic. Replicated data can be divided into two categories: read-only and writable data.
Read-only versions of replicated data allow revisions only to the first instance; subsequent enterprise data replications are then adjusted. Writable data can be altered, but the first instance is immediately changed.
Horizontally fragmented data involves the use of primary keys that refer to one record in the database. Horizontal fragmentation is usually reserved for situations in which business locations only need to access the database pertaining to their specific branch.
Vertically fragmented data involves using copies of primary keys that are available within each section of the database and are accessible to each branch. Vertically fragmented data is utilized when the branch of a business and the central location interact with the same accounts in different ways.
Reorganized data is data that has been adjusted or altered for decision support databases. Reorganized data is typically used when two different systems are handling transactions and decision support. Decision support systems can be difficult to maintain and online transaction processing requires reconfiguration when many requests are being made.
Separate schema data partitions the database and the software used to access it in order to fit different departments and situations. There is usually an overlap between different databases within separate schema data.
Examples of distributed databases
Though there are many distributed databases to choose from, some examples of distributed databases include Apache Ignite, Apache Cassandra, Apache HBase, Couchbase Server, Amazon SimpleDB, Clusterpoint, and FoundationDB.
Apache Ignite specializes in storing and computing large volumes of data across clusters of nodes. In 2014, Ignite was open sourced by GridGain Systems and later accepted into the Apache Incubator program. Apache Ignite's database uses RAM as the default storage and processing tier.
Apache Cassandra offers support for clusters that span multiple locations, and it features its own query language, Cassandra Query Language (CQL). Additionally, Cassandra's replication strategies are configurable.
Apache HBase runs on top of the Hadoop Distributed File System and provides a fault-tolerant way to store large quantities of sparse data. It also features compression, in-memory operation and Bloom filters on a per-column basis. HBase is not intended as a replacement for SQL database, although Apache Phoenix provides a SQL layer for HBase.
Couchbase Server is a NoSQL software package that is ideal for interactive applications that serve multiple concurrent users by creating, storing, retrieving, aggregating, manipulating and presenting data. To support these many application needs, Couchbase Server provides scalable key value and JSON document access.
Amazon SimpleDB is used as a web service with Amazon Elastic Compute Cloud and Amazon S3. Amazon SimpleDB enables developers to request and store data with minimal database management and administrative responsibility.
Clusterpoint removes the complexity, scalability issues and performance limitations of relational database architectures. Data is managed in XLM or JSON format using open APIs. Because Clusterpoint is a schema-free document database, it removes the scalability problems and performance issues that most relational database architectures face.
FoundationDB is a multimodel database designed around a core database that exposes an ordered key valued store with each transaction. These transactions support ACID properties and are capable of reading and writing keys that are stored on any machine within the cluster. Additional features appear in layers around this core.







