
yoshitaka272 - Fotolia
Using a LEFT OUTER JOIN vs. RIGHT OUTER JOIN in SQL
In this book excerpt, you'll learn LEFT OUTER JOIN vs. RIGHT OUTER JOIN techniques and find various examples for creating SQL queries that incorporate OUTER JOINs.
In this excerpt from SQL Queries for Mere Mortals: A Hands-On Guide to Data Manipulation in SQL, John L. Viescas and Michael J. Hernandez discuss the LEFT OUTER JOIN vs. the RIGHT OUTER JOIN and offer tips on how to use each of them in SQL statements. They also provide various examples of OUTER JOIN syntax to help guide database administrators and developers on the required SQL coding.
You'll generally use the OUTER JOIN form that asks for all the rows from one table or result set and any matching rows from a second table or result set. To do this, you specify either a LEFT OUTER JOIN or a RIGHT OUTER JOIN.
What's the difference between LEFT and RIGHT? Remember from the previous chapter that to specify an INNER JOIN on two tables, you name the first table, include the JOIN keyword, and then name the second table. When you begin building queries using OUTER JOIN, the SQL Standard considers the first table you name as the one on the "left," and the second table as the one on the "right." So, if you want all the rows from the first table and any matching rows from the second table, you'll use a LEFT OUTER JOIN. Conversely, if you want all the rows from the second table and any matching rows from the first table, you'll specify a RIGHT OUTER JOIN.
Syntax
Let's examine the syntax needed to build either a LEFT or RIGHT OUTER JOIN.
Using Tables
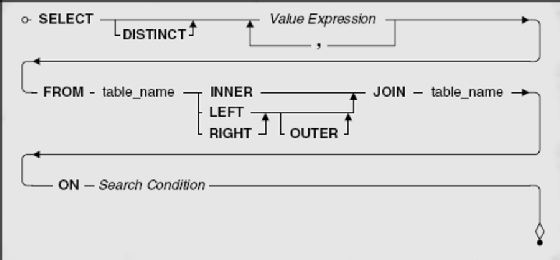
We'll start simply with defining an OUTER JOIN using tables. Figure 9–3 shows the syntax diagram for creating a query with an OUTER JOIN on two tables.
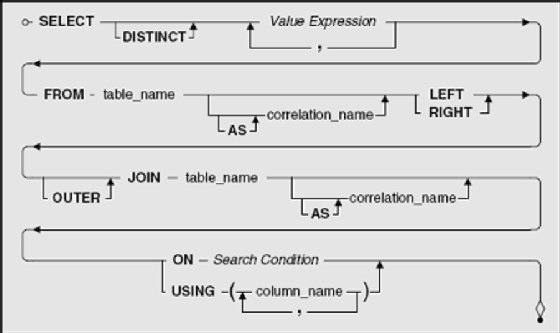
Just like INNER JOIN (covered in Chapter 8), all the action happens in the FROM clause. (We left out the WHERE and ORDER BY clauses for now to simplify things.) Instead of specifying a single table name, you specify two table names and link them with the JOIN keyword. If you do not specify the type of JOIN you want, your database system assumes you want an INNER JOIN. In this case, because you want an OUTER JOIN, you must explicitly state that you want either a LEFT JOIN or a RIGHT JOIN. The OUTER keyword is optional.
Note
For those of you following along with the complete syntax diagrams in Appendix A, SQL Standard Diagrams, note that we've pulled together the applicable parts (from Select Statement, Table Reference, and Joined Table) into simpler diagrams that explain the specific syntax we're discussing.
The critical part of any JOIN is the ON or USING clause that follows the second table and tells your database system how to perform the JOIN. To solve the JOIN, your database system logically combines every row in the first table with every row in the second table. (This combination of all rows from one table with all rows from a second table is called a Cartesian product.) It then applies the criteria in the ON or USING clause to find the matching rows to be returned. Because you asked for an OUTER JOIN, your database system also returns the unmatched rows from either the "left" or "right" table.
You learned about using a search condition to form a WHERE clause in Chapter 6, Filtering Your Data. You can use a search condition in the ON clause within a JOIN to specify a logical test that must be true in order to return any two linked rows. It only makes sense to write a search condition that compares at least one column from the first table with at least one column from the second table. Although you can write a very complex search condition, you can usually specify a simple equals comparison test on the primary key columns from one table with the foreign key columns from the other table.
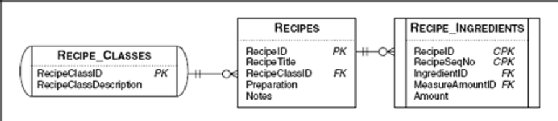
To keep things simple, let's start with the same recipe classes and recipes example we used in the last chapter. Remember that in a well-designed database, you should break out complex classification names into a second table and then link the names back to the primary subject table via a simple key value. In the Recipes sample database, recipe classes appear in a table separate from recipes. Figure 9–4 shows the relationship between the Recipe_Classes and Recipes tables.
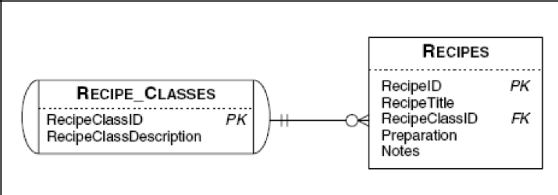
When you originally set up the kinds of recipes to save in your database, you might have started by entering all the recipe classes that came to mind. Now that you've entered a number of recipes, you might be interested in finding out which classes don't have any recipes entered yet. You might also be interested in listing all the recipe classes along with the names of recipes entered so far for each class. You can solve either problem with an OUTER JOIN.
Note
Throughout this chapter, we use the "Request/Translation/Clean Up/SQL" technique introduced in Chapter 4, Creating a Simple Query.
"Show me all the recipe types and any matching recipes in my database."
| Translation | Select recipe class description and recipe title from the recipe classes table left outer joined with the recipes table on recipe class ID in the recipe classes table matching recipe class ID in the recipes table |
| Clean Up | Select recipe class description from left outer join on recipe_ classes.recipe class ID |
| SQL | SELECT Recipe_Classes.RecipeClassDescription,Recipes.RecipeTitle FROM Recipe_Classes LEFT OUTER JOIN Recipes ON Recipe_Classes.RecipeClassID = Recipes.RecipeClassID |
When using multiple tables in your FROM clause, remember to qualify fully each column name with the table name wherever you use it so that it's absolutely clear which column from which table you want. Note that we had to qualify the name of RecipeClassID in the ON clause because there are two columns named RecipeClassID -- one in the Recipes table and one in the Recipe_Classes table.
Note
Although most commercial implementations of SQL support OUTER JOIN, some do not. If your database does not support OUTER JOIN, you can still solve the problem by listing all the tables you need in the FROM clause, then moving your search condition from the ON clause to the WHERE clause. You must consult your database documentation to learn the specific nonstandard syntax that your database requires to define the OUTER JOIN. For example, earlier versions of Microsoft SQL Server support this syntax. (Notice the asterisk in the WHERE clause.)
SELECT Recipe_Classes.RecipeClassDescription,
Recipes.RecipeTitle
FROM Recipe_Classes, Recipes
WHERE Recipe_Classes.RecipeClassID *=
Recipes.RecipeClassID
If you're using Oracle, the optional syntax is as follows. (Notice the plus sign in the WHERE clause.)
SELECT Recipe_Classes.RecipeClassDescription,
Recipes.RecipeTitle
FROM Recipe_Classes, Recipes
WHERE Recipe_Classes.RecipeClassID =
Recipes.RecipeClassID(+)
Quite frankly, these strange syntaxes were invented by database vendors that wanted to provide this feature long before a clearer syntax was defined in the SQL Standard. Thankfully, the SQL Standard syntax allows you to fully define the source for the final result set entirely within the FROM clause. Think of the FROM clause as fully defining a linked result set from which the database system obtains your answer. In the SQL Standard, you use the WHERE clause only to filter rows out of the result set defined by the FROM clause. Also, because the specific syntax for defining an OUTER JOIN via the WHERE clause varies by product, you might have to learn several different syntaxes if you work with multiple nonstandard products.
If you execute our example query in the Recipes sample database, you should see 16 rows returned. Because we didn't enter any soup recipes in the database, you'll get a Null value for RecipeTitle in the row where RecipeClassDescription is 'Soup'. To find only this one row, use this approach.
"List the recipe classes that do not yet have any recipes."
| Translation | Select recipe class description from the recipe classes table left outer joined with the recipes table on recipe class ID where recipe ID is empty |
| Clean Up | Select recipe class description from left outer join on recipe_classes.recipe class ID = recipes.recipe class ID where recipe ID is |
| SQL | SELECT Recipe_Classes.RecipeClassDescriptionFROM Recipe_ClassesLEFT OUTER JOIN RecipesON Recipe_Classes.RecipeClassID = Recipes.RecipeClassIDWHERE Recipes.RecipeID IS NULL |
If you think about it, we've just done a difference or EXCEPT operation (see Chapter 7) using a JOIN. It's somewhat like saying, "Show me all the recipe classes except the ones that already appear in the recipes table." The set diagram in Figure 9–5 should help you visualize what's going on.
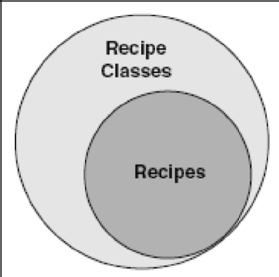
In Figure 9–5, all recipes have a recipe class, but some recipe classes exist for which no recipe has yet been defined. When we add the IS NULL test, we're asking for all the rows in the lighter outer circle that don't have any matches in the set of recipes represented by the darker inner circle.
Notice that the diagram for an OUTER JOIN on tables in Figure 9–3 also has the optional USING clause. If the matching columns in the two tables have the same name and you want to join only on equal values, you can use the USING clause and list the column names. Let's do the previous problem again with USING.
"Display the recipe classes that do not yet have any recipes."
| Translation | Select recipe class description from the recipe classes table left outer joined with the recipes table using recipe class ID where recipe ID is empty |
| Clean Up | Select recipe class description from left outer join where recipe ID is |
| SQL | SELECT Recipe_Classes.RecipeClassDescriptionFROM Recipe_ClassesLEFT OUTER JOIN Recipes USING (RecipeClassID)WHERE Recipes.RecipeID IS NULL |
The USING syntax is a lot simpler, isn't it? There's one small catch: Any column in the USING clause loses its table identity because the SQL Standard dictates that the database system must "coalesce" the two columns into a single column. In this example, there's only one RecipeClassID column as a result, so you can't reference Recipes.RecipeClassID or Recipe_Classes.RecipeClassID in the SELECT clause or any other clause.
Be aware that some database systems do not yet support USING. If you find that you can't use USING with your database, you can always get the same result with an ON clause and an equals comparison.
Note
The SQL Standard also defines a type of JOIN operation called a NATURAL JOIN. A NATURAL JOIN links the two specified tables by matching all the columns with the same name. If the only common columns are the linking columns and your database supports NATURAL JOIN, you can solve the example problem like this:
SELECT Recipe_Classes.RecipeClassDescription
FROM Recipe_Classes
NATURAL LEFT OUTER JOIN Recipes
WHERE Recipes.RecipeID IS NULL
Do not specify an ON or USING clause if you use the NATURAL keyword.
Embedding a SELECT Statement
As you recall from Chapter 8, most SQL implementations let you substitute an entire SELECT statement for any table name in your FROM clause. Of course, you must then assign a correlation name (see the section on assigning alias names in Chapter 8) so that the result of evaluating your embedded query has a name. Figure 9–6 shows how to assemble an OUTER JOIN clause using embedded SELECT statements.
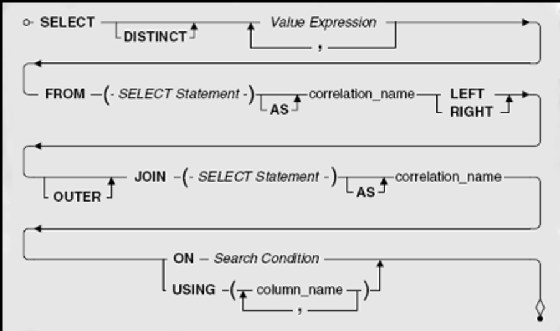
Note that a SELECT statement can include all query clauses except an ORDER BY clause. Also, you can mix and match SELECT statements with table names on either side of the OUTER JOIN keywords.
Let's look at the Recipes and Recipe_Classes tables again. For this example, let's also assume that you are interested only in classes Salads, Soups, and Main courses. Here's the query with the Recipe_Classes table filtered in a SELECT statement that participates in a LEFT OUTER JOIN with the Recipes table.
SQL
SELECT RCFiltered.ClassName, R.RecipeTitle
FROM
(SELECT RecipeClassID,
RecipeClassDescription AS ClassName
FROM Recipe_Classes AS RC
WHERE RC.ClassName = 'Salads'
OR RC.ClassName = 'Soup'
OR RC.ClassName = 'Main Course')
AS RCFiltered
LEFT OUTER JOIN Recipes AS R
ON RCFiltered.RecipeClassID = R.RecipeClassID
You must be careful when using a SELECT statement in a FROM clause. First, when you decide to substitute a SELECT statement for a table name, you must be sure to include not only the columns you want to appear in the final result but also any linking columns you need to perform the JOIN. That's why you see both RecipeClassID and RecipeClassDescription in the embedded statement. Just for fun, we gave RecipeClassDescription an alias name of ClassName in the embedded statement. As a result, the SELECT clause asks for ClassName rather than RecipeClassDescription. Note that the ON clause now references the correlation name (RCFiltered) of the embedded SELECT statement rather than the original name of the table or the correlation name we assigned the table inside the embedded SELECT statement.
As the query is stated for the actual Recipes sample database, you see one row with RecipeClassDescription of Soup with a Null value returned for RecipeTitle because there are no soup recipes in the sample database. We could just as easily have built a SELECT statement on the Recipes table on the right side of the OUTER JOIN. For example, we could have asked for recipes that contain the word "beef" in their titles, as in the following statement.
SQL
SELECT RCFiltered.ClassName, R.RecipeTitle
FROM
(SELECT RecipeClassID,
RecipeClassDescription AS ClassName
FROM Recipe_Classes AS RC
WHERE RC.ClassName = 'Salads'
OR RC.ClassName = 'Soup'
OR RC.ClassName = 'Main Course')
AS RCFiltered
LEFT OUTER JOIN
(SELECT Recipes.RecipeClassID, Recipes.Recipe
Title
FROM Recipes
WHERE Recipes.RecipeTitle LIKE '%beef%')
AS R
ON RCFiltered.RecipeClassID = R.RecipeClassID
Keep in mind that the LEFT OUTER JOIN asks for all rows from the result set or table on the left side of the JOIN, regardless of whether any matching rows exist on the right side. The previous query not only returns a Soup row with a Null RecipeTitle (because there are no soups in the database at all) but also a Salad row with a Null. You might conclude that there are no salad recipes in the database. Actually, there are salads in the database but no salads with "beef" in the title of the recipe!
Note
You might have noticed that you can enter a full search condition as part of the ON clause in a JOIN. This is absolutely true, so it is perfectly legal in the SQL Standard to solve the example problem as follows.
SELECT Recipe_Classes.RecipeClassDescription,
Recipes.RecipeTitle
FROM Recipe_Classes
LEFT OUTER JOIN Recipes
ON Recipe_Classes.RecipeClassID =
Recipes.RecipeClassID
AND
(Recipe_Classes.RecipeClassDescription = 'Salads'
OR Recipe_Classes.RecipeClassDescription = 'Soup'
OR Recipe_Classes.RecipeClassDescription =
'Main Course')
AND Recipes.RecipeTitle LIKE '%beef%'
Unfortunately, we have discovered that some major implementations of SQL solve this problem incorrectly or do not accept this syntax at all! Therefore, we recommend that you always enter in the search condition in the ON clause only criteria that compare columns from the two tables or result sets. If you want to filter the rows from the underlying tables, do so with a separate search condition in a WHERE clause in an embedded SELECT statement.
Embedding JOINs within JOINs
Although you can solve many problems by linking just two tables, many times you'll need to link three, four, or more tables to get all the data to solve your request. For example, you might want to fetch all the relevant information about recipes -- the type of recipe, the recipe name, and all the ingredients for the recipe -- in one query. Now that you understand what you can do with an OUTER JOIN, you might also want to list all recipe classes -- even those that have no recipes defined yet -- and all the details about recipes and their ingredients. Figure 9–7 shows all the tables needed to answer this request.
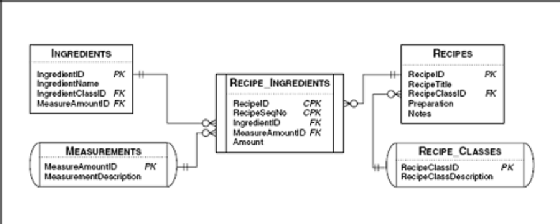
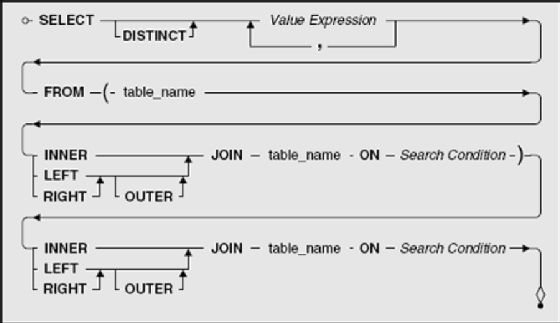
Looks like you need data from five different tables! Just as in Chapter 8, you can do this by constructing a more complex FROM clause, embedding JOIN clauses within JOIN clauses. Here's the trick: Everywhere you can specify a table name, you can also specify an entire JOIN clause surrounded with parentheses. Figure 9–8 shows a simplified version of joining two tables. (We've left off the correlation name clauses and chosen the ON clause to form a simple INNER or OUTER JOIN of two tables.)
To add a third table to the mix, just place an open parenthesis before the first table name, add a close parenthesis after the search condition, and then insert another JOIN, a table name, the ON keyword, and another search condition. Figure 9–9 (on page 306) shows how to do this.
If you think about it, the JOIN of two tables inside the parentheses forms a logical table, or inner result set. This result set now takes the place of the first simple table name in Figure 9–8. You can continue this process of enclosing an entire JOIN clause in parentheses and then adding another JOIN keyword, table name, ON keyword, and search condition until you have all the result sets you need. Let's make a request that needs data from all the tables shown in Figure 9–7 and see how it turns out. (You might use this type of request for a report that lists all recipe types with details about the recipes in each type.)
"I need all the recipe types, and then the matching recipe names, preparation instructions, ingredient names, ingredient step numbers, ingredient quantities, and ingredient measurements from my recipes database, sorted in recipe title and step number sequence."
| Translation | Select the recipe class description, recipe title, preparation instructions, ingredient name, recipe sequence number, amount, and measurement description from the recipe classes table left outer joined with the recipes table on recipe class ID in the recipe classes table matching recipe ID in the recipes table, then joined with the recipe ingredients table on recipe ID in the recipes table matching recipe ID in the recipe ingredients table, then joined with the ingredients table on ingredient ID in the ingredients table matching ingredient ID in the recipe ingredients table, and then finally joined with the measurements table on measurement amount ID in the measurements table matching measurement amount ID in the recipe ingredients table, order by recipe title and recipe sequence number |
| Clean Up | Select |
| SQL | SELECT Recipe_Classes.RecipeClassDescription,Recipes.RecipeTitle, Recipes.Preparation,Ingredients.IngredientName,Recipe_Ingredients.RecipeSeqNo,Recipe_Ingredients.Amount,Measurements.MeasurementDescriptionFROM (((Recipe_ClassesLEFT OUTER JOIN RecipesON Recipe_Classes.RecipeClassID =Recipes.RecipeClassID)INNER JOIN Recipe_IngredientsON Recipes.RecipeID = Recipe_Ingredients.RecipeID)INNER JOIN IngredientsON Ingredients.IngredientID =Recipe_Ingredients.IngredientID)INNER JOIN Measurements ON Measurements.MeasureAmountID = Recipe_Ingredients.MeasureAmountIDORDER BY RecipeTitle, RecipeSeqNo |
In truth, you can substitute an entire JOIN of two tables anywhere you might otherwise place only a table name. In Figure 9–9, we implied that you must first join the first table with the second table and then join that result with the third table. You could also join the second and third tables first (as long as the third table is, in fact, related to the second table and not the first one) and then perform the final JOIN with the first table. Figure 9–10 (on page 308) shows you this alternate method.

To solve the request we just showed you using five tables, we could have also stated the SQL as follows.
SQL
SELECT Recipe_Classes.RecipeClassDescription,
Recipes.RecipeTitle, Recipes.Preparation,
Ingredients.IngredientName,
Recipe_Ingredients.RecipeSeqNo,
Recipe_Ingredients.Amount,
Measurements.MeasurementDescription
FROM Recipe_Classes
LEFT OUTER JOIN
(((Recipes
INNER JOIN Recipe_Ingredients
ON Recipes.RecipeID = Recipe_Ingredients.RecipeID)
INNER JOIN Ingredients
ON Ingredients.IngredientID =
Recipe_Ingredients.IngredientID)
INNER JOIN Measurements
ON Measurements.MeasureAmountID =
Recipe_Ingredients.MeasureAmountID)
ON Recipe_Classes.RecipeClassID =
Recipes.RecipeClassID
ORDER BY RecipeTitle, RecipeSeqNo
Remember that the optimizers in some database systems are sensitive to the sequence of the JOIN definitions. If your query with many JOINs is taking a long time to execute on a large database, it might run faster if you change the sequence of JOINs in your SQL statement.
You might have noticed that we used only one OUTER JOIN in the previous multiple-JOIN examples. You're probably wondering whether it's possible or even makes sense to use more than one OUTER JOIN in a complex JOIN. Let's assume that there are not only some recipe classes that don't have matching recipe rows but also some recipes that don't have any ingredients defined yet. In the previous example, you won't see any rows from the Recipes table that do not have any matching rows in the Recipe_Ingredients table because the INNER JOIN eliminates them. Let's ask for all recipes as well.
"I need all the recipe types, and then all the recipe names and preparation instructions, and then any matching ingredient names, ingredient step numbers, ingredient quantities, and ingredient measurements from my recipes database, sorted in recipe title and step number sequence."
| Translation | Select the recipe class description, recipe title, preparation instructions, ingredient name, recipe sequence number, amount, and measurement description from the recipe classes table left outer joined with the recipes table on recipe class ID in the recipe classes table matching recipe class ID in the recipes table, then left outer joined with the recipe ingredients table on recipe ID in the recipes table matching recipe ID in the recipe ingredients table, then joined with the ingredients table on ingredient ID in the ingredients table matching ingredient ID in the recipe ingredients table, and then finally joined with the measurements table on measurement amount ID in the measurements table matching measurement amount ID in the recipe ingredients table, order by recipe title and recipe sequence number |
| Clean Up | Select |
| SQL | SELECT Recipe_Classes.RecipeClassDescription,Recipes.RecipeTitle, Recipes.Preparation, Ingredients.IngredientName, Recipe_Ingredients.RecipeSeqNo, Recipe_Ingredients.Amount, Measurements.MeasurementDescriptionFROM (((Recipe_Classes LEFT OUTER JOIN Recipes ON Recipe_Classes.RecipeClassID = Recipes.RecipeClassID) LEFT OUTER JOIN Recipe_Ingredients ON Recipes.RecipeID = Recipe_Ingredients.RecipeID) INNER JOIN Ingredients ON Ingredients.IngredientID = Recipe_Ingredients.IngredientID) INNER JOIN Measurements ON Measurements.MeasureAmountID = Recipe_Ingredients.MeasureAmountIDORDER BY RecipeTitle, RecipeSeqNo |
Be careful! This sort of multiple OUTER JOIN works as expected only if you're following a path of one-to-many relationships. Let's look at the relationships between Recipe_Classes, Recipes, and Recipe_Ingredients again, as shown in Figure 9–11.
You might see a one-to-many relationship sometimes called a parent-child relationship. Each parent row (on the "one" side of the relationship) might have zero or more children rows (on the "many" side of the relationship). Unless you have orphaned rows on the "many" side (for example, a row in Recipes that has a Null in its RecipeClassID column), every row in the child table should have a matching row in the parent table. So it makes sense to say Recipe_Classes LEFT JOIN Recipes to pick up any parent rows in Recipe_Classes that don't have any children yet in Recipes. Recipe_Classes RIGHT JOIN Recipes should (barring any orphaned rows) give you the same result as an INNER JOIN.
Likewise, it makes sense to ask for Recipes LEFT JOIN Recipe_ Ingredients because you might have some recipes for which no ingredients have yet been entered. Recipes RIGHT JOIN Recipe_Ingredients doesn't work because the linking column (RecipeID) in Recipe_Ingredients is also part of that table's compound primary key. Therefore, you are guaranteed to have no orphaned rows in Recipe_Ingredients because no column in a primary key can contain a Null value.
Now, let's take it one step further and ask for all ingredients, including those not yet included in any recipes. First, take a close look at the relationships between the tables, including the Ingredients table, as shown in Figure 9–12
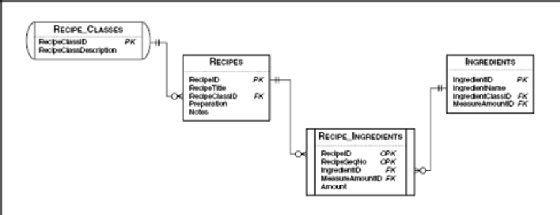
Let's try this request. (Caution: There's a trap here!)
"I need all the recipe types, and then all the recipe names and preparation instructions, and then any matching ingredient step numbers, ingredient quantities, and ingredient measurements, and finally all ingredient names from my recipes database, sorted in recipe title and step number sequence."
| Translation | Select the recipe class description, recipe title, preparation instructions, ingredient name, recipe sequence number, amount, and measurement description from the recipe classes table left outer joined with the recipes table on recipe class ID in the recipe classes table matches class ID in the recipes table, then left outer joined with the recipe ingredients table on recipe ID in the recipes table matches recipe ID in the recipe ingredients table, then joined with the measurements table on measurement amount ID in the measurements table matches measurement amount ID in the measurements table, and then finally right outer joined with the ingredients table on ingredient ID in the ingredients table matches ingredient ID in the recipe ingredients table, order by recipe title and recipe sequence number |
| Clean Up | Select |
| SQL | SELECT Recipe_Classes.RecipeClassDescription,Recipes.RecipeTitle, Recipes.Preparation, Ingredients.IngredientName, Recipe_Ingredients.RecipeSeqNo, Recipe_Ingredients.Amount, Measurements.MeasurementDescriptionFROM (((Recipe_Classes LEFT OUTER JOIN Recipes ON Recipe_Classes.RecipeClassID = Recipes.RecipeClassID) LEFT OUTER JOIN Recipe_Ingredients ON Recipes.RecipeID = Recipe_Ingredients.RecipeID) INNER JOIN Measurements ON Measurements.MeasureAmountID =Recipe_Ingredients.MeasureAmountID) RIGHT OUTER JOIN Ingredients ON Ingredients.IngredientID = Recipe_Ingredients.IngredientID ORDER BY RecipeTitle, RecipeSeqNo |
Do you think this will work? Actually, the answer is a resounding NO! Most database systems analyze the entire FROM clause and then try to determine the most efficient way to assemble the table links. Let's assume, however, that the database decides to fully honor how we've grouped the JOINs within parentheses. This means that the database system will work from the innermost JOIN first (Recipe_Classes joined with Recipes) and then work outward.
Because some rows in Recipe_Classes might not have any matching rows in Recipes, this first JOIN returns rows that have a Null value in RecipeClassID. Looking back at Figure 9–12, you can see that there's a one-to-many relationship between Recipe_Classes and Recipes. Unless some recipes exist that haven't been assigned a recipe class, we should get all the rows from the Recipes table anyway! The next JOIN with the Recipe_Ingredients table also asks for a LEFT OUTER JOIN. We want all the rows, regardless of any Null values, from the previous JOIN (of Recipe_Classes with Recipes) and any matching rows in Recipe_Ingredients. Again, because some rows in Recipe_Classes might not have matching rows in Recipes or some rows in Recipes might not have matching rows in Recipe_Ingredients, several of the rows might have a Null in the IngredientID column from the Recipe_Ingredients table. What we're doing with both JOINs is "walking down" the one-to-many relationships from Recipe_Classes to Recipes and then from Recipes to Recipe_Ingredients. So far, so good. (By the way, the final INNER JOIN with Measurements is inconsequential -- we know that all Ingredients have a valid MeasureAmountID.)
Now the trouble starts. The final RIGHT OUTER JOIN asks for all the rows from Ingredients and any matching rows from the result of the previous JOINs. Remember from Chapter 5 that a Null is a very special value -- it cannot be equal to any other value, not even another Null. When we ask for all the rows in Ingredients, the IngredientID in all these rows has a non-Null value. None of the rows from the previous JOIN that have a Null in IngredientID will match at all, so the final JOIN throws them away! You will see any ingredient that isn't used yet in any recipe, but you won't see recipe classes that have no recipes or recipes that have no ingredients.
If your database system decides to solve the query by performing the JOINs in a different order, you might see recipe classes that have no recipes and recipes that have no ingredients, but you won't see ingredients not yet used in any recipe because of the Null matching problem. Some database systems might recognize this logic problem and refuse to solve your query at all -- you'll see something like an "ambiguous OUTER JOINs" error message. The problem we're now experiencing results from trying to "walk back up" a many-to-one relationship with an OUTER JOIN going in the other direction. Walking down the hill is easy, but walking back up the other side requires special tools. What's the solution to this problem? Read on to the next section to find out!

This chapter excerpt from SQL Queries for Mere Mortals: A Hands-On Guide to Data Manipulation in SQL (2nd Edition) by John L. Viescas and Michael J. Hernandez, is printed with permission from Addison-Wesley Professional, Copyright 2007.
Click here for the chapter download or purchase the book here.







