hashing

What is hashing?
Hashing is the process of transforming any given key or a string of characters into another value. This is usually represented by a shorter, fixed-length value or key that represents and makes it easier to find or employ the original string.
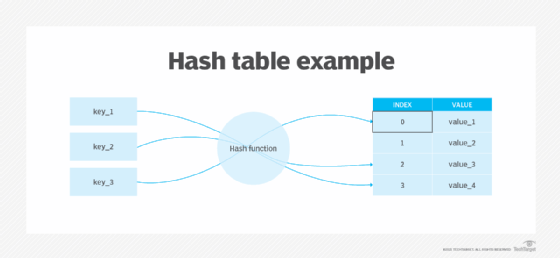
The most popular use for hashing is the implementation of hash tables. A hash table stores key and value pairs in a list that is accessible through its index. Because key and value pairs are unlimited, the hash function will map the keys to the table size. A hash value then becomes the index for a specific element.
A hash function generates new values according to a mathematical hashing algorithm, known as a hash value or simply a hash. To prevent the conversion of hash back into the original key, a good hash always uses a one-way hashing algorithm.
Hashing is relevant to -- but not limited to -- data indexing and retrieval, digital signatures, cybersecurity and cryptography.
What is hashing used for?
Data retrieval
Hashing uses functions or algorithms to map object data to a representative integer value. A hash can then be used to narrow down searches when locating these items on that object data map.
For example, in hash tables, developers store data -- perhaps a customer record -- in the form of key and value pairs. The key helps identify the data and operates as an input to the hashing function, while the hash code or the integer is then mapped to a fixed size.
Hash tables support functions that include the following:
- insert (key, value)
- get (key)
- delete (key)
Digital signatures
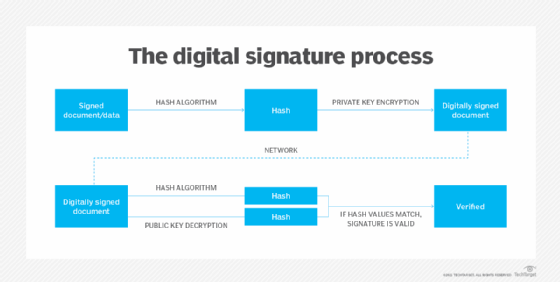
In addition to enabling rapid data retrieval, hashing helps encrypt and decrypt digital signatures used to authenticate message senders and receivers. In this scenario, a hash function transforms the digital signature before both the hashed value (known as a message digest) and the signature are sent in separate transmissions to the receiver.
Upon receipt, the same hash function derives the message digest from the signature, which is then compared with the transmitted message digest to ensure both are the same. In a one-way hashing operation, the hash function indexes the original value or key and enables access to data associated with a specific value or key that is retrieved.
What is hashing in data structure?
Dewey Decimal classification has worked well in libraries for many years, and the underlying concept works just as well in computer science. Software engineers can save both file space and time by shrinking the original data assets and input strings to short alphanumeric hash keys.
When someone is looking for an item on a data map, hashing helps narrow down the search. In this scenario, hash codes generate an index to store values. So, here, hashing is used to index and retrieve information from a database because it helps accelerate the process; it is much easier to find an item using its shorter hashed key than its original value.
What is hashing in cybersecurity?
Many encryption algorithms use hashing to enhance cybersecurity. Hashed strings and inputs are meaningless to hackers without a decryption key.
For example, if hackers breach a database and find data like "John Doe, Social Security number 273-76-1989," they can immediately use that information for their nefarious activities. However, a hashed value like "a87b3" is useless for threat actors unless they have a key to decipher it.
As such, hashing helps secure passwords stored in a database.
What is hashing in cryptography?
cryptography uses multiple hash functions to secure data. Some of the most popular cryptographic hashes include the following:
- Secure Hash Algorithm 1 (SHA-1)
- Secure Hash Algorithm 2 (SHA-2)
- Secure Hash Algorithm 3 (SHA-3)
- MD2
- MD4
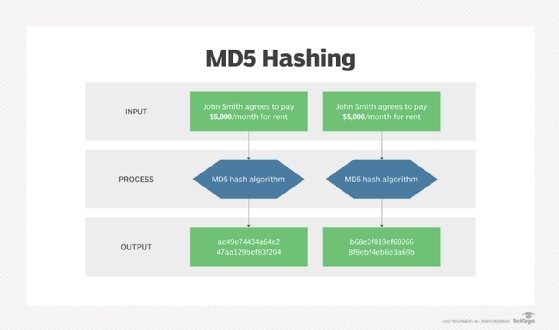
- MD5
Message-digest hash functions like MD2, MD4 and MD5 help hash digital signatures. Once hashed, the signature is transformed into a shorter value called a message digest.
Secure Hash Algorithm (SHA) is a standard algorithm used to create a larger (160-bit) message digest. While it is like message-digest hash function MD4 -- and is good at database storage and retrieval -- this is not the best approach for cryptographic or error-checking purposes. SHA-2 is used to create a larger (224-bit) message digest. SHA-3 is SHA-2's successor.
What is a collision?
Hashing in cybersecurity demands unidirectional processes that use a one-way hashing algorithm. It is a crucial step in stopping threat actors from reverse engineering a hash back to its original state. At the same time, two keys can also generate an identical hash. This phenomenon is called a collision.
A good hash function never produces the same hash value from two different inputs. As such, a hash function that comes with an extremely low risk of collision is considered acceptable.
Open addressing and separate chaining are two ways of dealing with collisions when they occur. Open addressing handles collisions by storing all data in the hash table itself and then seeking out availability in the next spot created by the algorithm.
Open addressing methods include:
- double hashing
- linear probing
- quadratic probing
Separate chaining, by contrast, avoids collisions by making every hash table cell point to linked lists of records with identical hash function values.
To further ensure the uniqueness of encrypted outputs, cybersecurity professionals can also add random data into the hash function. This approach, known as "salting," guarantees a unique output even when the inputs are identical.
Salting obstructs bad actors from accessing non-unique passwords. This is because each hash value is unique, even when users reuse their passwords. Salting adds another layer of security to thwart rainbow table attacks.
Hashing can also be used when analyzing or preventing file tampering. This is because each original file generates a hash and stores it within the file data. When a receiver receives the file and hash together, it can check the hash to determine if the file was compromised. If someone manipulated the file in transit, the hash would reflect that change.







